最近投入了大量摸鱼时间重构博客。现在大概告一段落了,向大家介绍一下整体的技术选型和具体实现的简要思路。
TLDR:JAMStack 实践,使用最新最潮的前端元框架 Astro,魔改 Astro Paper 主题,搭配 Headless CMS Directus,直通对接思源笔记内容同步,自建 SeaweedFS 分布式文件系统暴露 S3 API 作为图床后端,使用 WebP Server 作为图床前端反代,部署 Cloudflare Pages,实现高度客制化的博客体验。
你可以从这里开始访问我的博客:https://clouder0.com/zh-cn/posts/my-new-blog
Introduction
一路走来,我的博客架构换了一茬又一茬,虽然内容好像更新地也不是很勤快……不,其实还是有持续输出内容的吧!
但是,我现在越来越忙了,也可能是越来越懒了,手动更新博客显然不是什么好的方案,毕竟我目前的内容创作主要集中于:
- 在思源笔记中写一点为自己记录的内容。顺便,写作是思考的媒介,我也很习惯边写东西边做研究。
- 写完之后,可能随手复制粘贴发到知乎上。
复制粘贴发送到知乎上,和复制粘贴发送到博客上有什么区别呢,好像也没什么区别,但如果想要支援多平台的话,感觉就很麻烦了。而且我确实很讨厌把差不多的事情重复做很多次。
所以还是来点纯粹的自动化吧!
History
那么讲一讲我博客的历史……曾经用过的方案包括:
-
WordPress,感觉已经是上个时代的产物了。庞大、臃肿,功能过于丰富,破事很多,成本也不低。而且商业化气息浓厚,各种付费主题插件之类的,总之对个人博客场景感觉不是很好的选择。
- BTW,我对 PHP 没什么好感(
-
typecho,相比 WordPress 当然是清爽简洁了许多,但是……动态博客对个人场景来说还是比较 overhead,因为主体静态内容明明是可以随便 CDN 分发的才对。而且感觉功能又有点过于简陋了。
- 同样也是上个时代的产物了。唉,PHP.
-
Hexo,静态博客是一阵风啊,突如其来地席卷了大江南北。当然,Hexo 是好的,但当初还是遇到了一些问题,主要是:构建时间长。
- 对于现在的我来说,不使用 Hexo 的主要原因可能是……定制化没那么方便?基于模板的方案,不是很自由。
- 主要就是不是很自由吧。
-
Hugo,构建速度非常的神清气爽啊,上个博客就是这个版本的。
- 主要问题还是定制不太方便,用的是 Golang 的模板语法,原来尝试改过一点主题,真是令人痛苦万分啊。
Arch
那么,归纳一下我的需求:
- 以静态为主,但要能够结合一些动态内容。最好能直接渲染成 HTML,但支持在里面内嵌一些 Component,走前后端分离架构那套玩法来添加一点动态内容。
- 高度可定制化,需要什么小功能就能自己搓。
当初我听说过有一个框架叫做 Gatsby,不过现在更流行的是 Astro. Astro 虽然可以用来做博客,不过更多时候会拿来做一些企业的 Landing Page. 它的设计架构非常的漂亮,整体上说:
- 同时支持 Server Component 和 Client Component,可以混合动静态内容。
- 使用类似 JSX 的语法,写起来令人倍感亲切,比学奇奇怪怪的模板方便多了。
- 在 Static Site Generation 阶段,可以直接执行 JavaScript 代码,调用给出的 API 即可,非常非常灵活啊。
是的,所以理论上在 Astro 里面我们可以做到这样的事情:
- 在 build 阶段,调用 API 拉取 CMS 的内容。根据 API 调用返回值直接构建静态网站。
而如果你不想静态构建的话,Server Side Rendering 也是改个配置的事情。非常好文明。
Implementation
在实际的搭建过程中,顺序大概是这样的:
- 先用 Astro 把博客的前端跑起来。
- 搭建 Directus,折腾 Astro 成功对接 Directus 的后端内容。
- 手搓一个小工具,实现思源笔记导出内容至 Directus 中。
- 手搓博客的 i18n、评论区、RSS、OgImage 等功能。
- 跑 SeaweedFS,跑 WebP Server 把图床跑起来。
- 使用思源笔记的发布插件对接 S3 Backend 方便上传图片。
Astro
虽然 Astro 挺好的, 主要是它可以非常方便地结合前端技术栈,爱用啥用啥。但还是有一些 Drawbacks,目前我注意到的几点不足是:
-
拉取 Remote Content 的 Content Layer API 还不是很成熟,许多文档缺失。虽然已经可以用了,但官方没有暴露方便的 Markdown Render 接口,导致拉取了远端的 Markdown 内容还要自己想办法渲染。
- 渲染 Remote Markdown 最后的解决方案是我在官方 Discord Channel 的聊天记录里找到的…
-
Incremental Build 虽然有,但只支持本地 Markdown 文件,只要打开增量构建,Remote Content 会直接消失。果然是非常 Experimental 的 Feature 啊。
-
默认没有异步构建,或者说默认的 Concurrent Number 为 1,导致如果你的 Single Page Build 过程中有阻塞工作,总构建时长就会非常令人感叹。
-
开放的 API 感觉缺了不少东西,比如说缺少为使用者提供的 Cache API 之类的,只能自己脏脏地乱写。
-
没有足够开箱即用的 i18n 支持,虽然有 i18n router,但是灵活度差强人意,而且文档中给的方案也并不好。
Whatever,里面的大部分问题都被我想办法解决掉了。
i18n
具体探索掠过不谈,直接讲目前的 Solution:
使用 paraglidejs,一个 i18n 库,在 yml 中写翻译,然后 compile 成 js 文件,就可以直接在 Astro 中调用了。
但你依然需要为不同的语言生成不同的 static files,要做到这一点的话,可以添加一层路由:
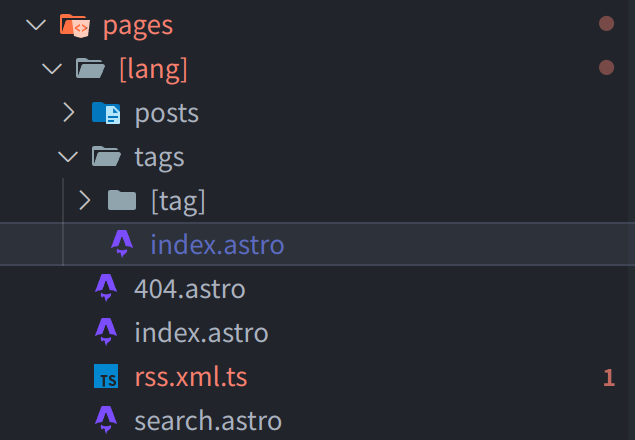
然后在 export static path 的时候:
import { availableLanguageTags, languageTag } from "paraglide/runtime";
import * as m from "paraglide/messages.js";
const posts = [
...(await getCollection("blog")),
...(await getCollection("directus_blog")),
];
const tags = getUniqueTags(posts.filter(p => p.data.lang === languageTag()));
export function getStaticPaths() {
return availableLanguageTags.map(lang => ({ params: { lang } }));
}
大概是这么个意思,为不同的 language 生成不同的路由。
需要注意:Astro 默认的 Content 必须有 unique slug,而这意味着 [lang]/[slug] 这样的路由会导致 zh-cn/mypost 和 en/mypost 只能指向同一个 mypost.md,这个时候一个解决方案是:写文件的时候把 slug 开头加上 [lang]-,然后生成路由的时候删掉。
for (const lang of ["zh-cn", "en"]) {
if (o.slug.startsWith(`${lang}-`)) {
return o.slug.slice(lang.length + 1);
}
}
return o.slug;我自己搓了一个简单的切换 language 的小组件。还有各种乱七八糟的细节,这里就不展开了,这个方向是能走通的。
评论区
评论区使用了 Giscus,说实话体验舒适不算好啊草。我尝试 Self Host,但是——
一个小小的评论区就有 2000+ 个依赖包?构建出来的 Docker Image 直接上 G?属实是非常的操蛋啊。
Anyway,还是使用了。放弃了 self host,因为没跑起来,我怀疑是不支持 Bun runtime. 使用了官方构建的版本。
官方的内嵌 script 跟 Astro 搭配比较灵车,建议使用 React 版本。
我自己附加包了一层根据全局的 language 切换 Giscus 语言的功能,当然还有主题切换的时候需要跟着切换,这也是一个样式小细节。用 useEffect 注册一个 Event Listener,在 theme switch 的时候 emit event 就行了。
这里曾经遇到了一些灵车的问题,后来发现是 Cloudflare Rocket Loader 会导致 Astro 在 view transition 时 js 脚本执行异常,关了 Rocket Loader 就行。
Content Layer & Remote Markdown
现在推荐的拉取远端资源的方法是使用 Content Layer,不仅可以定义 schema、接入 Astro 的 Content 生态,而且有很方便的内置方法实现 Incremental Loading,不过渲染似乎没法省略掉。
拉取的 Markdown 内容要接入 Astro 中显示,还得自己处理渲染成 HTML. Astro 目前没有给出公开的、能够使用框架配置的 Markdown Render 方法,官方文档中建议使用第三方的 Markdown 渲染。。。但我在 Discord 上学到了这种做法:
import { createMarkdownProcessor } from "@astrojs/markdown-remark";
const preprocessor = await createMarkdownProcessor(ctx.config.markdown);
const rendered = await preprocessor.render(post.content);Content Loader 这部分的文档还不是很详细,提供一个拉取 Directus 的例子:
export const directusLoader = (conf: {
url: string;
username: string;
password: string;
}): Loader => {
const client = createDirectus<DirectusSchema>(conf.url)
.with(rest())
.with(authentication());
return {
name: "directus_loader",
load: async ctx => {
// ctx.store.clear();
// ctx.meta.delete("last-modified");
await client.login(conf.username, conf.password);
const last_modified =
ctx.meta.get("last-modified") ?? new Date(1900, 0, 0).toISOString();
ctx.logger.info(`Last modified: ${last_modified}`);
const res = (
await client.request(
readItems("BlogPosts", {
filter: {
_or: [
{
date_created: {
_gt: last_modified,
},
},
{
date_updated: {
_gt: last_modified,
},
},
],
},
})
)
).map(x => ({
...x,
date_created: new Date(x.date_created),
date_updated: x.date_updated ? new Date(x.date_updated) : null,
}));
console.log(res);
const preprocessor = await createMarkdownProcessor(ctx.config.markdown);
for (const post of res) {
const data = await ctx.parseData({ id: post.id, data: post });
const digest = ctx.generateDigest(data);
const rendered = await preprocessor.render(post.content);
ctx.store.set({
id: post.id,
data: data,
body: post.content,
rendered: {
html: rendered.code,
metadata: {
frontmatter: rendered.metadata.frontmatter,
headings: rendered.metadata.headings,
imagePaths: [...rendered.metadata.imagePaths],
},
},
digest: digest,
});
ctx.logger.info(`Fetched post: ${post.title}`);
}
ctx.meta.set("last-modified", new Date().toISOString());
},
schema: directusSchema,
};
};
然后在 Content Collection 配置中写:
const directus_blog = defineCollection({
type: "content_layer",
loader: directusLoader({
url: DIRECTUS.url,
username: DIRECTUS.user,
password: DIRECTUS.password,
}),
});
Open Graph Image
Astro Paper 内置了相关的功能,但有两个主要的 Drawback:
- 每次生成的时候都会去动态拉取 Google Fonts,在国内网络环境下非常灵车,而且比较缓慢。
- 每次都动态生成 OgImage,但实际上这种 Pure Function 明明很方便缓存。
因此自己搓了一个缓存层,并且切换成了使用本地字体,然后切换成使用 Noto Serif,因为原版字体不支持中文。
Astro 没有给开发者提供 Cache 相关的 API,所以我决定直接写到系统 tmp 文件夹里面去。
这里注意,如果存在 Concurrency,有可能两个相同的 key 同时判定 Cache 不存在,然后进入了生成流程,然后开始写入,此时发生 race condition. 解决方案是在第一个 check cache 后决定需要生成就加上锁,让后续的那个不再生成,而是等待前者生成然后直接读取。
不过实际上没有测试过,自我感觉没问题。Coroutine 还是比 Multithread 好处理很多,但并不意味着我们可以瞎几把写,异步该有的问题还是会有。
什么,Astro 默认单 Coroutine 处理?那没事了。
import * as os from "node:os";
import * as crypto from "node:crypto";
import * as fs from "node:fs/promises";
const key_locks = new Map<string, Promise<Buffer>>();
export const useCache = () => {
const path_prefix = `${os.tmpdir()}/blogcache`;
return {
read: (key: object, genenrator: () => Promise<Buffer>) => {
return (async () => {
const sha256 = crypto.createHash("sha256");
sha256.update(JSON.stringify(key));
const shakey = sha256.digest("hex");
if (key_locks.has(shakey)) {
const res = await key_locks.get(shakey);
// console.log("HIT MEM CACHE")
return res;
}
const path = `${path_prefix}/${shakey}`;
try {
const res = await fs.readFile(path);
// console.log("HIT DISK CACHE")
return res;
} catch (e) {
const res = genenrator();
key_locks.set(shakey, res);
const awaited_res = await res;
// console.log("generate success")
// make dir first
await fs.mkdir(path_prefix, { recursive: true });
await fs.writeFile(path, awaited_res);
// console.log("WRITE DISK CACHE")
return awaited_res;
}
})();回车。
},
};
};
KaTeX
KaTeX 接入的话,实际上我们可以做 Server Side Rendering,只需要接入 KaTeX 的 css 就能完美渲染了。用 remark rehype 的插件就行,这部分没什么特殊的,略过了。
Astro 这边暂且主要就做了这些工作,还有一些细小的工作没有写出来。
Directus
选用 Directus 作为我的 Headless CMS. 为什么需要一个 Headless CMS?
- 我的内容需要有一个中心化的 Source of Truth.
- 我希望能够从各种各样的信息源输出内容。比如笔记软件同步文章,比如随手记的 idea. 简单的说,我希望将多个信息源的内容通过 API 调用上传到 Headless CMS 做集中,然后博客再直接从 Headless CMS 渲染内容。
- 我不太喜欢使用 Git 管理一切内容,因为需要管理 commits,比较麻烦,而且不是很方便 API 接入。一般而言,我并没有管理内容版本的需求。
可以说这是一层 Abstraction Layer. 如果不使用 Headless CMS 的话,当然我也可以直接在 Astro 中写从信息源拉数据、渲染的功能。但这就非常脏,支持多个信息源的时候也没那么方便,而且拉信息源的构建过程就必须对信息源有访问权限。比如跑 CI/CD 构建的时候,Actor 就对我本地的笔记软件 Backend 没有访问权限,所以不是一个很好的方案。
Directus 在这里扮演的主要是一个简单的数据库的功能。虽然有一个 Admin Panel,理论上我也可以在里面修改内容……但其实思源笔记才是我主要的内容输出端。
当然,以后可能会接入更多的内容输入。
读读官方文档就会用了,还是很好上手的。不过嘛,功能本身也不多,只是一个 thin wrapper.
思源笔记发布
Oneway sync,做一个简单的增量更新就可以了。
整体思路是:
- 使用
directus-last-update 这个自定义属性来判断是否已经更新至 Directus. - 若某个 Document Block 在思源笔记的更新时间晚于其被标注的 directus-last-update 属性值,则将其同步至 Directus,并覆写时间戳。
当然,实际上我还加入了一些 metadata 相关的属性项,以便在思源笔记这边向 directus 写入属性。不过这里就涉及到一个 two-way sync 的问题,如果在 Directus 上更新内容的话就一定会被思源笔记这边覆写了,除非做一个 directus2siyuan 的写回,有点麻烦,暂且不管。
把核心的 SQL 语句放出来吧,其他的都是 trivial work:
SELECT * FROM 'blocks' b INNER JOIN
(SELECT block_id, value AS 'last_update' FROM 'attributes' WHERE name == 'custom-directus-last-update') a
ON b.id == a.block_id AND b.updated > a.last_update AND b.type == 'd'图床
自建 S3,Minio 有点太重了,我选择使用 SeaweedFS 和 Filer.
暴露出 S3 API 之后,用 WebP Server 包一层,可以做自动转 webp 之类的优化操作,然后再接入 caddy.
思源这边的话,有一个 PicGo 插件可以接入 S3 Backend,上传图片也很方便。
Deploy
目前的 Deploy 主要分四步:
- 在思源这边更新好 metadata.
- 调用脚本同步至 Directus.
- 根据 Directus 内容构建 Static Site.
- 上传至 Cloudflare Pages.
前两步因为需要访问思源笔记的数据,只能在我的本地完成,或者说我倾向于在本地完成。后两步则不一定。
考虑过是否要作 CD,不过想了想还是大道至简,在我的某台 vps 上搭好了环境,然后 alias 一条命令 SSH 上去执行就完事了。
最终日常的博客更新流程就是:
- 按 F12 打开我的 Drop Down Terminal.
- 输入
s2d && blogdeploy. - 回车。
- 完成。
Additional Notes…
强烈推荐使用思源笔记的发布插件,一键发布多平台,虽然感觉有一些方面做得还略有不足,但已经算是可用了。
目前知乎内容均由该插件直接上传。